
非常におおまかな時系列データの簡易的な作り方を紹介します。
プログラミング技術が低いので、全て自動とはいかないので調整は手打ちする部分があります。
よろしければご覧ください。
必要なライブラリ
Pythonで使うライブラリは以下です。
よく使われるものですね。
Pythonのバージョンは3.8
各種ライブラリをimportします。
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import randam
作り方
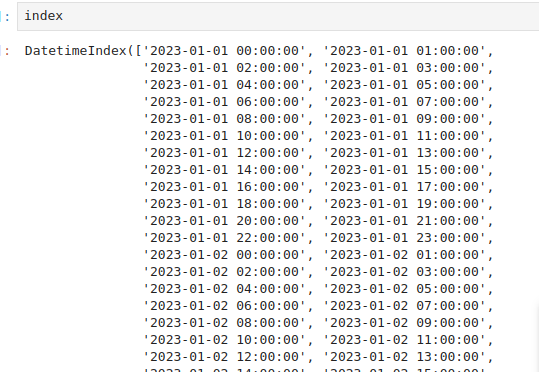
次にデータフレームを作り、日付と時間を生成します。それをインデックスとします。
index = pd.date_range(“2023-01-01″,”2023-01-03″,freq=”H”)
Hは時間単位なので。、1日単位の場合はDになるます。
次は乱数を使って1日のデータを作り出します。
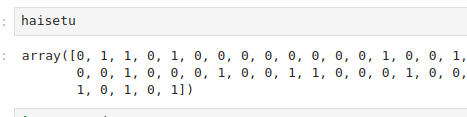
排泄回数を作ってみます。0と1で有無ということにします。乱数は固定。
行の長さは(len(index))で長さを先ほど作った日付と時間のINDEXを使います。
np.random.seed(48)
haisetu = np.random.randint(0,2,len(index))
こんな感じです。
df1 = pd.DataFrame(haisetu,index=index,columns=[“haisetu”])
次は水分摂取量を作ってみます。
この場合は、下限値と上限値を0から150に設定。
50cc単位で摂った量とします。
簡単に記述したいのでリスト内包表記を使っています。
random.seed(46)
suibun = [random.randrange(0,150,50) for i in range(len(index))]
こんな感じですね。夜中まで飲んでるのと、量が偏っているので後に修正が必要そうです。
df2 = pd.DataFrame(suibun,index=index,columns=[“suibun”])

さらに睡眠状態や認知症周辺行動もよくあるので追記するとそれらしくなりますかね。
今回はデータフレームに空のカラムを作ります。
0と1のランダムな数値をrandom_number()で作り
後は、イメージする対象者を考えながら
寝ているか否かを0と1で後で修正すると完成。
df3[“suimin”] = 0
df3 = df3[“suimin”].apply(lambda x: random_number())
こんな感じになりました。
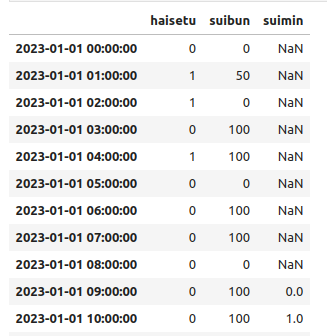
確認すると
おや、なんだか一部floatになっていたり欠損値が出たりしていますな。
欠損値にはfillnaで穴埋め
全体をastypeでデータ型を一括変換。
さて、
全てを結合させます。
df_concat = pd.concat([df1, df2, df3],axis=1)
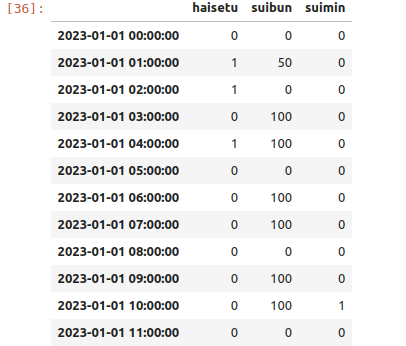
ザックリですが完成。
ではグラフにしてみましょう。
import matplotlib.pyplot as plt
乱数ではありますがデータが作れましたよ。
to csvでcsvファイルを出力すると表計算ソフトなどで調整ができます。
今の私ではこれが限界です・゜・(ノД`)・゜・。
ベースが出来たので、水分量や排泄量の偏ったケースに調整すれば何とか使えそうです。
このままだと相関係数が良くて0.03なので使えないかな?
こんなのを使って機械学習などを試してみたい >w<)9
改良の余地あり
私はそんなにプログラミンが上手くないので、微調整は出力したcsvファイルを直接イメージに近づけながら行うことしかできません(。w。
乱数を固定したい場合は、randam.seed(0)などを追記して適切な数値で固定するといいです。
プログラミングが得意な方は、特定の時間だけ睡眠を0、1のどちらか操作するなど行えば眠っているか否かなどがさっと作れるのではないでしょうか。
もっと活用出来るデータセットにしたいなぁ・w・)0
/


コメント